Ribosomes, essential cellular machinery, utilize start stop codons to initiate and terminate protein synthesis. The genetic code, interpreted by transfer RNA (tRNA) molecules, relies on specific sequences signaling the beginning and end of translation. Messenger RNA (mRNA) molecules carry the coded instructions; these instructions are delimited by, yes, those very important start stop codons. Understanding gene expression requires a thorough grasp of these signals; the accurate translation of genetic information depends entirely on the precise recognition of start stop codons.
Life, in its astounding complexity, hinges on a remarkably simple yet elegant code: the genetic code. This code, embodied within the sequence of DNA and RNA, dictates the synthesis of proteins, the workhorses of the cell. Understanding this code is paramount to understanding life itself.
The Genetic Code: A Blueprint for Protein Synthesis
The genetic code is a set of rules used by living cells to translate information encoded within genetic material (DNA or RNA sequences) into proteins. Specifically, it dictates how sequences of nucleotide triplets, called codons, specify which amino acid will be added next during protein synthesis.
This process, known as protein synthesis (or translation), is the cornerstone of cellular function, enabling everything from enzymatic reactions to structural support. Without it, cells could not create the molecules they need to survive and function.
The genetic code’s elegance lies in its simplicity; a mere four nucleotide bases (adenine, guanine, cytosine, and thymine/uracil) combine to form 64 possible codons, each specifying either an amino acid or a signal to start or stop protein synthesis.
Start and Stop Codons: Defining the Boundaries
Within the genetic code, start and stop codons hold a special significance. They act as punctuation marks, defining the precise beginning and end of each protein-coding sequence.
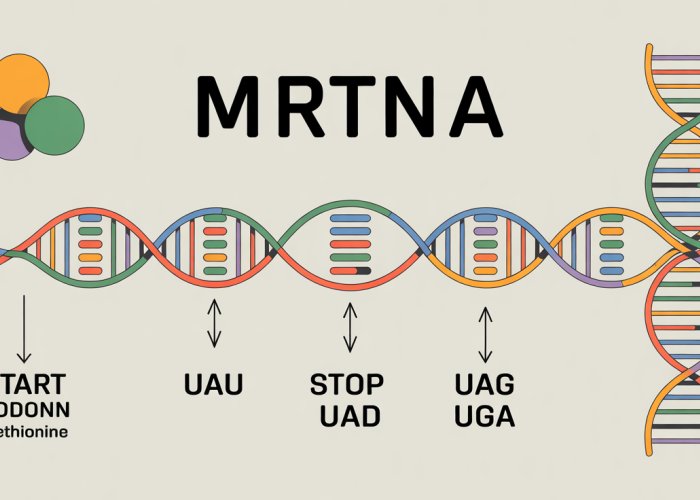
Start codons (most commonly AUG) signal the ribosome, the protein synthesis machinery, to begin translating the mRNA sequence. The AUG codon also encodes for the amino acid methionine, which is typically the first amino acid in a newly synthesized protein.
Conversely, stop codons (UAA, UAG, and UGA) signal the ribosome to terminate translation, releasing the newly formed polypeptide chain. Unlike start codons, stop codons do not code for any amino acid. Instead, they are recognized by release factors, which mediate the termination process.
These initiation and termination signals are absolutely crucial. Without them, the ribosome would not know where to begin or end, leading to the production of non-functional proteins or the disruption of cellular processes. They ensure that the correct protein sequence is synthesized, contributing to proper protein folding, function, and overall cellular health.
In essence, start and stop codons are the gatekeepers of protein synthesis, ensuring that the genetic message is accurately translated into functional proteins.
A Comprehensive Overview
This guide aims to provide a comprehensive exploration of start and stop codons, their function, and their significance in the intricate machinery of biology. We will delve into the mechanisms by which these codons exert their influence, exploring their roles in defining the reading frame, impacting gene expression, and ultimately shaping the landscape of life itself.
Life, in its astounding complexity, hinges on a remarkably simple yet elegant code: the genetic code. This code, embodied within the sequence of DNA and RNA, dictates the synthesis of proteins, the workhorses of the cell. Understanding this code is paramount to understanding life itself.
With the fundamental role of the genetic code established, it’s time to zoom in and explore the specific signals that govern the initiation of protein synthesis. These signals are the start codons, most notably AUG, the master switch that flips the cellular machinery into action, dictating where the protein sequence begins.
The Initiation Signal: Decoding the Start Codon (AUG)
The process of translating genetic information into functional proteins is a highly orchestrated event, demanding precise control over where it begins and ends. The start codon, most famously AUG, serves as the universal initiator, marking the precise point where the ribosome should begin reading the mRNA sequence to build a protein.
But where exactly is this crucial sequence located? The start codon AUG resides on the messenger RNA (mRNA), the intermediary molecule that carries the genetic instructions from the DNA in the nucleus to the ribosomes in the cytoplasm, where protein synthesis takes place.
AUG: The Maestro of Initiation
The start codon AUG doesn’t just tell the ribosome to start; it also specifies which amino acid should be added as the first building block of the nascent protein.
This amino acid is methionine. Therefore, nearly all newly synthesized proteins start with methionine.
Methionine: The Inaugural Amino Acid
Methionine is a sulfur-containing amino acid, and it plays a crucial role not only as the initiator, but also in the folding and structure of the protein. It’s important to note that while most proteins begin with methionine, it is often removed later during post-translational modification.
A Prokaryotic Twist: Modified Methionine
In prokaryotes, the initiating methionine is often a modified form called N-formylmethionine (fMet). This modification is crucial for the initiation of protein synthesis in bacteria, as it allows the bacterial ribosome to specifically recognize the start codon.
tRNA’s Crucial Role: Delivering Methionine
Transfer RNA (tRNA) molecules act as adapter molecules. They are responsible for recognizing and delivering the correct amino acid to the ribosome based on the mRNA sequence. A special initiator tRNA is charged with methionine (or fMet in prokaryotes). It then binds to the start codon AUG on the mRNA.
This initiator tRNA is uniquely capable of binding directly to the ribosome’s P-site (peptidyl site), setting the stage for the addition of subsequent amino acids.
Defining the Reading Frame
Perhaps the most critical role of the start codon is that it defines the reading frame. The reading frame is the specific sequence of codons that will be translated into the protein. mRNA sequence can be read in three possible reading frames, depending on where the ribosome starts.
Only one of these reading frames will produce the correct protein. By correctly identifying the AUG codon, the ribosome ensures that it reads the mRNA in the correct frame, preventing the synthesis of a non-functional or harmful protein. Without the accurate definition of the reading frame by the start codon, the protein synthesis process would be entirely meaningless.
Methionine: The Inaugural Amino Acid
With the initiation of protein synthesis precisely orchestrated, the cellular machinery diligently adds amino acids to the growing polypeptide chain, guided by the sequence of codons on the mRNA. However, this elongation process can’t continue indefinitely. The cell needs a way to signal that the protein is complete, a molecular "full stop" to prevent the ribosome from reading beyond the coding sequence. That’s where stop codons come into play, signaling the end of translation.
Termination Time: Understanding Stop Codons (UAA, UAG, UGA)
While the start codon AUG initiates the intricate dance of protein synthesis, the termination of this process is equally crucial. The cell utilizes a set of three stop codons – UAA, UAG, and UGA – to signal the end of translation. These codons, unlike the other 61 codons in the genetic code, do not code for any amino acid.
Signaling the End of Translation
When the ribosome encounters one of these stop codons on the mRNA, it signals the end of the protein sequence. No tRNA molecule carries a corresponding anticodon to pair with the stop codon.
This is where the process takes an interesting turn. Instead of adding another amino acid, the ribosome recruits release factors.
Termination Factors (Release Factors): Molecular Stop Signs
Termination factors, also known as release factors (RFs), are specialized proteins that recognize stop codons. In eukaryotes, a single release factor, eRF1, recognizes all three stop codons. Prokaryotes, on the other hand, use two release factors, RF1 and RF2, to recognize UAA and UAG, and UAA and UGA, respectively. A third release factor, RF3, helps facilitate the termination process in prokaryotes.
These release factors bind to the ribosome at the A-site (aminoacyl-tRNA binding site), effectively mimicking the shape of a tRNA molecule. However, instead of carrying an amino acid, they trigger a series of events that lead to the hydrolysis of the bond between the tRNA in the P-site (peptidyl-tRNA binding site) and the polypeptide chain.
This hydrolysis releases the newly synthesized polypeptide from the ribosome.
The Absence of tRNA: A Critical Distinction
The mechanism of termination is heavily dependent on the fact that no tRNA molecule recognizes the stop codons. If there were a tRNA that could bind to UAA, UAG, or UGA, translation would continue, potentially leading to elongated, non-functional proteins.
This absence highlights the elegance and precision of the genetic code. The termination process is a carefully orchestrated event, dependent on the lack of a corresponding tRNA and the presence of release factors.
The Fate of mRNA Post-Termination
Once the polypeptide chain is released and the ribosome disassociates, what happens to the mRNA molecule? In eukaryotes, the mRNA molecule is typically subjected to degradation pathways.
This prevents further translation of the same mRNA molecule and allows the cell to recycle the building blocks for new RNA synthesis.
The degradation process often involves the removal of the poly(A) tail, a sequence of adenine nucleotides added to the 3′ end of the mRNA during processing, followed by enzymatic digestion of the mRNA molecule itself.
In essence, the life cycle of mRNA comes full circle, from transcription to translation and, ultimately, to degradation, ensuring a continuous flow of genetic information and controlled protein synthesis.
Termination factors efficiently detach the newly synthesized polypeptide from the ribosome, but what about the machinery involved in the intricate dance of protein synthesis? The process depends on a sophisticated interplay between several key players. Let’s delve deeper into the structure and function of these molecular machines.
The Protein Synthesis Machinery: Ribosomes, mRNA, and tRNA
Protein synthesis, also known as translation, is a highly coordinated process that requires the concerted action of several key cellular components. These include ribosomes, the sites of protein synthesis; messenger RNA (mRNA), which carries the genetic code from DNA; and transfer RNA (tRNA), which brings the correct amino acids to the ribosome based on the mRNA sequence. Understanding the individual roles of these components is crucial to grasping the overall mechanism of protein synthesis.
Ribosomes: The Protein Synthesis Factories
Ribosomes are complex molecular machines found in all living cells, serving as the primary site of protein synthesis. They are composed of two subunits, a large subunit and a small subunit, each containing ribosomal RNA (rRNA) and ribosomal proteins.
The ribosome’s structure facilitates the binding of mRNA and tRNA molecules, enabling the translation of the genetic code into a polypeptide chain.
Ribosome Structure and Function
In eukaryotes, the ribosome is an 80S complex, while in prokaryotes, it is a 70S complex (the "S" stands for Svedberg units, a measure of sedimentation rate and thus, indirectly, of size). The small subunit is responsible for binding to the mRNA and ensuring correct codon-anticodon pairing between the mRNA and tRNA.
The large subunit catalyzes the formation of peptide bonds between amino acids. Ribosomes contain three binding sites for tRNA: the A (aminoacyl) site, the P (peptidyl) site, and the E (exit) site. These sites play a critical role in the sequential addition of amino acids to the growing polypeptide chain.
mRNA: Carrying the Genetic Message
Messenger RNA (mRNA) serves as the intermediary between DNA and the ribosome, carrying the genetic information needed to synthesize a protein.
mRNA molecules are transcribed from DNA in the nucleus (in eukaryotes) and then transported to the cytoplasm, where translation occurs.
The Structure and Role of mRNA
The mRNA molecule contains a sequence of codons, each consisting of three nucleotides, that specifies the order of amino acids in the protein. The sequence of codons on the mRNA is read by the ribosome during translation, guiding the addition of specific amino acids to the growing polypeptide chain.
Notably, mRNA molecules also contain untranslated regions (UTRs) at the 5′ and 3′ ends, which play roles in regulating translation efficiency and mRNA stability.
tRNA: Adapters for Amino Acid Delivery
Transfer RNA (tRNA) molecules act as adapters that bring the correct amino acids to the ribosome based on the sequence of codons on the mRNA. Each tRNA molecule has a specific anticodon sequence that can base-pair with a complementary codon on the mRNA.
Decoding the Genetic Code with tRNA
Each tRNA molecule is also attached to a specific amino acid, ensuring that the correct amino acid is incorporated into the growing polypeptide chain. The process of attaching the correct amino acid to a tRNA molecule is called aminoacylation or tRNA charging, and it is catalyzed by aminoacyl-tRNA synthetases.
There are different tRNA molecules for each of the 20 amino acids used in protein synthesis.
The Orchestrated Process of Translation
Translation is a cyclical process, with the ribosome moving along the mRNA in a 5′ to 3′ direction, reading each codon and adding the corresponding amino acid to the polypeptide chain. The process can be broken down into three main stages: initiation, elongation, and termination.
Understanding the structure and function of ribosomes, mRNA, and tRNA is essential for appreciating the complexity and precision of protein synthesis. These molecular machines work together in a highly coordinated manner to ensure that the genetic information encoded in DNA is accurately translated into functional proteins.
Framing the Code: The Importance of the Reading Frame
With the key components of protein synthesis in place, how does the cell ensure that the correct amino acids are strung together in the right order? The answer lies in the concept of the reading frame, an essential aspect of the genetic code that dictates how mRNA sequences are interpreted.
Understanding the Reading Frame
The reading frame defines how the nucleotide sequence of an mRNA molecule is divided into codons, each consisting of three nucleotides.
Think of it as a sentence where each word has three letters. If you start reading the sentence from the wrong place, the words become nonsensical.
Similarly, if translation begins at the wrong nucleotide, the resulting protein will likely be non-functional or even harmful.
The Start Codon as the Anchor
The start codon (AUG) is not just an initiator; it is the linchpin that establishes the correct reading frame.
By marking the precise starting point for translation, the start codon ensures that the ribosome reads the mRNA sequence in the correct triplets.
This is crucial for the accurate decoding of the genetic information.
Open Reading Frames (ORFs): Windows to Protein Sequences
Within an mRNA sequence, an open reading frame (ORF) is a region that has the potential to be translated into a protein.
It is characterized by a start codon (AUG) followed by a series of codons and ending with a stop codon (UAA, UAG, or UGA).
Identifying ORFs is a key step in gene annotation. It helps researchers predict which regions of a genome encode proteins.
The Devastating Consequences of Frameshift Mutations
The importance of maintaining the correct reading frame is dramatically illustrated by frameshift mutations.
These mutations, caused by insertions or deletions of nucleotides that are not multiples of three, disrupt the reading frame.
This leads to a completely altered amino acid sequence downstream of the mutation.
Imagine shifting all the letters in our three-letter-word sentence forward or backward by one position. The words would become garbled, and the meaning would be lost.
The resulting protein is almost always non-functional and can even have toxic effects on the cell.
Frameshift mutations highlight the exquisite precision with which the cell must maintain the integrity of the reading frame to ensure accurate protein synthesis.
Frameshift mutations dramatically illustrate just how crucial the correct reading frame is to producing functional proteins. But the story of codons and their impact on the proteome doesn’t end there. The genetic code, while universal, exhibits nuances that significantly influence the efficiency and precision of protein synthesis. This brings us to the fascinating concept of codon usage bias, a phenomenon that reveals how organisms subtly fine-tune their genetic machinery.
Beyond the Basics: Understanding Codon Usage Bias
Codon usage bias refers to the observation that different organisms exhibit preferences for specific codons when encoding the same amino acid. This means that even though multiple codons can translate to the same amino acid (a property known as the degeneracy of the genetic code), certain codons are used more frequently than others.
Unequal Opportunities: Delving into Codon Preference
The genetic code is redundant, meaning that most amino acids are encoded by more than one codon. For example, leucine is encoded by six different codons: UUA, UUG, CUU, CUC, CUA, and CUG. While all these codons will result in the incorporation of leucine into a growing polypeptide chain, organisms often show a distinct preference for one or two of these codons.
This non-random usage of synonymous codons is what we call codon usage bias. It’s not simply a matter of chance; it reflects an underlying evolutionary adaptation.
The Why Behind the What: Factors Influencing Codon Usage Bias
Several factors contribute to codon usage bias:
-
tRNA Availability: The abundance of specific tRNA molecules in a cell often correlates with the usage frequency of their corresponding codons. If a particular tRNA is highly abundant, its corresponding codon will likely be used more frequently.
-
Translation Efficiency: Certain codons may be translated more efficiently than others due to differences in tRNA binding affinity or ribosome transit time. This can impact the overall speed and accuracy of protein synthesis.
-
mRNA Structure and Stability: Codon usage can influence the secondary structure of mRNA molecules. Certain codons may promote mRNA folding that enhances stability and translational efficiency.
-
Mutational Biases: The underlying mutation rates within a genome can also contribute to codon usage bias. If certain nucleotide changes are more frequent, they can drive the evolution of codon preferences.
Gene Expression’s Silent Partner
Codon usage bias has a significant impact on gene expression levels. Genes that are rich in preferred codons tend to be translated more efficiently, leading to higher protein production. Conversely, genes with a high proportion of rare codons may be translated more slowly, resulting in lower protein levels.
This effect is particularly pronounced in highly expressed genes, where the use of optimal codons can dramatically increase the efficiency of protein synthesis.
Codon Optimization: A Powerful Tool
Understanding codon usage bias has led to the development of codon optimization strategies. By modifying the codon composition of a gene to match the preferred codon usage of a specific organism, researchers can significantly enhance protein expression.
This technique is widely used in biotechnology and synthetic biology to improve the production of recombinant proteins, develop more effective vaccines, and engineer novel biological systems.
The Evolutionary Perspective
From an evolutionary standpoint, codon usage bias reflects a balancing act between translational efficiency and the cost of maintaining a diverse pool of tRNA molecules. Organisms adapt their codon usage patterns to optimize protein synthesis in their specific cellular environment. This highlights the intricate interplay between genetic code, translation machinery, and evolutionary forces.
Frameshift mutations dramatically illustrate just how crucial the correct reading frame is to producing functional proteins. But the story of codons and their impact on the proteome doesn’t end there. The genetic code, while universal, exhibits nuances that significantly influence the efficiency and precision of protein synthesis. This brings us to the fascinating concept of codon usage bias, a phenomenon that reveals how organisms subtly fine-tune their genetic machinery.
The Broader Impact: Significance in Biology and Beyond
Start and stop codons are not merely molecular punctuation marks. They are fundamental gatekeepers, dictating the flow of genetic information into functional proteins. Their influence permeates nearly every aspect of biology, from the simplest unicellular organism to the most complex multicellular life forms. The fidelity with which these codons are recognized and acted upon has profound consequences for cellular health and overall organismal fitness.
Ensuring Accurate Protein Synthesis: A Foundation for Life
The primary and most direct impact of start and stop codons lies in ensuring the accuracy of protein synthesis. Without a precise start codon, the ribosome would initiate translation at an incorrect location. This would likely lead to the production of a non-functional, truncated, or altogether aberrant protein.
Similarly, the timely recognition of a stop codon is critical. If translation continues beyond the intended termination point, the resulting protein might be elongated. This could disrupt its structure, function, and even its interactions with other cellular components.
The repercussions of such errors can range from subtle metabolic imbalances to severe developmental defects and disease. The integrity of the proteome hinges on the correct interpretation of these signals.
Gene Expression and Regulation: A Symphony of Control
Start and stop codons also play a crucial role in gene expression and its regulation. The efficiency with which a gene is translated into protein depends, in part, on the context surrounding these codons.
For example, the sequence immediately upstream of the start codon (known as the Kozak sequence in eukaryotes) can influence the efficiency of ribosome binding and translation initiation. Similarly, the specific stop codon used can affect mRNA stability and decay rates.
Furthermore, the presence of premature stop codons (nonsense mutations) can trigger mRNA degradation pathways. These pathways, such as nonsense-mediated decay (NMD), serve as a quality control mechanism. They eliminate transcripts that are likely to produce non-functional proteins.
Fine-Tuning Gene Expression
The influence of start and stop codons extends beyond simple on/off switches. They contribute to the fine-tuning of gene expression levels. By modulating the efficiency of translation initiation and termination, cells can precisely control the amount of protein produced from a given gene. This is essential for maintaining cellular homeostasis and responding to environmental cues.
In essence, start and stop codons are integral components of the complex regulatory networks that govern gene expression. Their proper function is essential for maintaining cellular health, development, and adaptation. They are far more than simple signals; they are the cornerstones of a functional and adaptable proteome.
Frequently Asked Questions: Decoding Start Stop Codons
What exactly are start and stop codons and why are they important?
Start codons signal the beginning of protein synthesis during translation, telling the ribosome where to start reading the mRNA sequence. Stop codons, on the other hand, signal the end of translation, causing the ribosome to release the newly formed protein. Start stop codons are therefore essential for defining the boundaries of a gene.
How many different stop codons are there?
There are three different stop codons: UAA, UAG, and UGA. These sequences do not code for any amino acid and instead, signal the termination of translation. All three are recognized by release factors, leading to the detachment of the polypeptide chain.
Does the start codon always code for the same amino acid?
Yes, the start codon, typically AUG, also codes for the amino acid methionine (Met). In eukaryotes, this is usually the first amino acid in a newly synthesized protein. However, in some cases, methionine might be removed later during protein processing.
What happens if a mutation creates a premature stop codon?
A mutation that creates a premature stop codon will result in a truncated protein, meaning a protein that is shorter than it should be. This often leads to a non-functional protein, and can have significant consequences for the cell, potentially disrupting cellular processes. The location of premature stop codons influences the stability of the mRNA transcript.
So, there you have it – your ultimate decoding guide to start stop codons! Hopefully, you feel a bit more confident navigating the world of genetics now. Go forth and explore, and remember, we’re all just strung together with As, Ts, Gs, and Cs… and, of course, those crucial start stop codons!